Кластеризация и ее применение для анализа финансово-экономического состояния отрасли растениеводства в регионах РФ
Clustering applications in financial and economic analysis of the crop production in the Russian regions

Авторы
Аннотация
С использованием комплекса методов математического моделирования, многомерного-статистического анализа, нечётких множеств проведен анализ финансово-экономического состояния отрасли растениеводство в регионах РФ. Опираясь на результаты корреляционного, факторного, кластерного анализа и статистические показатели Федеральной службы государственной статистики разработана система показателей, отражающих финансово-экономическое состояние отрасли сельского хозяйства в регионе РФ. Проведена кластеризация регионов России по выделенным факторам на пять групп, дана качественная и количественная характеристика каждому кластеру.
Ключевые слова
моделирование, кластеризация, нечеткие множества, сельское хозяйство, регионы РФ, финансово-экономическое состояние.
Рекомендуемая ссылка
Громов Владислав Владимирович. Кластеризация и ее применение для анализа финансово-экономического состояния отрасли растениеводства в регионах РФ // Современные технологии управления. ISSN 2226-9339. — №8 (32). Номер статьи: 3202. Дата публикации: 08.08.2013. Режим доступа: https://sovman.ru/article/3202/
Authors
Abstract
We used the complex mathematical modeling, multivariate statistical-analysis, fuzzy sets to analyze the financial and economic state of the crop production in Russian regions. We developed a system of indicators, detecting the state agricultural sector in the region, based on the results of correlation, factor, cluster analysis and statistics of the Federal State Statistics Service. We performed clustering analyses to divide regions of Russia on selected factors into five groups. A qualitative and quantitative characteristics of each cluster was received.
Keywords
modeling, clustering, fuzzy sets, agriculture, the regions of the Russian Federation, the financial and economic situation.
Suggested citation
Gromov Vladislav Vladimirovich. Clustering applications in financial and economic analysis of the crop production in the Russian regions // Modern Management Technology. ISSN 2226-9339. — №8 (32). Art. # 3202. Date issued: 08.08.2013. Available at: https://sovman.ru/article/3202/
Региональные особенности развития АПК, которые основываются на природно-климатических, географических, производственно-экономических, ресурсных, структурных и прочих особенностях конкретного региона, порождают не только различия в производственных, инвестиционных условиях, но и в подходах к решению проблем АПК [1]. Негативным фактором при этом является неопределенность, информационная непрозрачность и сложность в оценке финансово-экономического состояния отрасли в регионе.
Одним из самых популярных инструментов оценок финансовой стабильности, экономического состояния региона в целом или его отдельных отраслей, являются рейтинги, которые присваиваются всем субъектам РФ. Показатели рейтинга в компактной и емкой форме характеризуют состояние и перспективные тенденции изменения деятельности региона, играя роль индикаторов для принятия решений, установления и поддержания деловых отношений. Минсельхоз России и Российская академия сельскохозяйственных наук составляют рейтинг АПК регионов по показателям эффективности сельскохозяйственного производства.
Рейтинг составляется на основе анализа шести критериев в АПК [3]: валовая продукция сельского хозяйства в расчёте на одного занятого в сельском хозяйстве, отношение выручки от продажи товаров, работ и услуг к стоимости основных средств на начало года, уровень рентабельности по всей деятельности сельхозорганизаций, удельный вес прибыльных организаций в их общем числе, коэффициент относительной финансовой устойчивости, отношение заработной платы в сельском хозяйстве к заработной плате в среднем по экономике субъекта РФ.
На наш взгляд, данные методики имеют ряд недочетов и недостатков. Во-первых, очень часто используется ранжирование по исследуемым показателям. Во-вторых, отсутствует предварительный анализ исследуемых показателей. Также в данных методиках не используются современные методы многомерного статистического анализа и интеллектуальных систем, которые уже давно подтвердили свою эффективность в зарубежных исследованиях. Рейтинги, присвоенные по таким методикам, безусловно, способны определить лидеров и аутсайдеров, но могут дать весьма общую картину состояния региона и не способны адекватно определить состояние отрасли в отдельно взятом регионе. Чтобы провести комплексный анализ, который будет учитывать многомерные статистические данные, необходимо использовать методы корреляционного, факторного, кластерного анализа данных, которые позволят выделить исследуемую выборку по группам (кластерам), позволят говорить о существовании таких групп.
В связи с этим создание собственной адекватной оценочной системы регионов по уровню их финансово-экономического состояния является актуальной задачей. Для решения подобной задачи, на наш взгляд, целесообразно использовать методы многомерного статистического анализа[2], нечетких продукционных систем [5]. В качестве исходных данных мы будем использовать центральную базу Федеральной службы государственной статистики.
Под термином «состояние отрасли» мы понимаем экономическую категорию, отражающую финансово-экономическое состояние отрасли, характеризуемое, на фиксированный момент времени, значениями следующих основных харктеристик: произведенная продукция, эффективность деятельности и другими количественными и качественными характеристиками и позволяющими ответить на следующие вопросы:
- насколько эффективна деятельность региона в отрасли?
- каков производственный потенциал отралси?
В ходе исследования нами будут использоваться прикладные программы Statictica [2] и Matlab [5].
На первом этапе в качестве показателей, характеризующих финансово-экономическое состояние отрасли в регионе РФ, выбираются значения коэффициентов из статистического сборника «Регионы России. Социально-экономические показатели 2012.» Федеральной службы государственной статистики (Росстата) [4]:
X1 — Продукция растениеводства, млн. руб.;
X2- Сальдированный финансовый результат организаций, млн. руб.;
X3 — Рентабельность проданных товаров, продукции, %;
X4 — Посевные сельскохозяйственных культур площади, тыс. гектаров.
X5 — Валовой сбор сельскохозяйственных культур., тыс. т.
X6 – Внесение удобрений минеральных и органических, т.
С помощью соответствующей процедуры в программе Statistica проведем нормализацию (стандартизацию) переменных – приведение к общему масштабу единиц исчисления.
На втором этапе исследования с помощью метода главных компонент [2], без вращения выделим фактор, который объединит финансовые показатели x2 и x3.
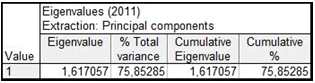
Рисунок 1 – Анализ собственного значения фактора
Собственное значение нового фактора равно 1,61 (рисунок 1). Данный фактор объясняет 75,85% от общей дисперсии. Следовательно, данные переменные можно объединить в один фактор, который будет линейной комбинацией факторов x2 и x3. Назовем данный фактор FIN.
На третьем этапе исследования проведем кластерный анализ по получившимся факторам. Мы будем использовать два метода кластеризации: k-средних и fuzzy c-means.
В алгоритме k-средних (k-means) строится k кластеров, расположенных на возможно больших расстояниях друг от друга. Данный метод подтверждает гипотезы относительно числа кластеров. Выбор числа k базируется на результатах исследований, экспертной оценке.
Предположим, что наша выборка по регионам состоит из трех кластеров: Как видно из рисунка 2, наше предположение о существовании трех кластеров верно: центры кластеров расположены на достаточно большом расстоянии друг от друга (евклидово расстояние).
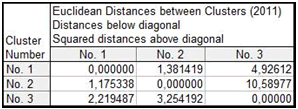
Рисунок 2– Расстояние между кластерами (3 кластера)
Далее выделим 5 кластеров из нашей выборки. Результаты представлены на рисунке 3. В данном случае центры кластеров уже не так далеки друг от друга, но, тем не менее, явно прослеживаются 5 групп.
Гипотеза о существовании подтверждается евклидовым расстоянием и квадратом евклидового расстояния между кластерами (рисунок 4) и таблицей дисперсионного анализа (рисунок 5). Во второй таблице приведены значения межгрупповых (Between SS) и внутригрупповых (Within SS) дисперсий признаков. Чем меньше значение внутригрупповой дисперсии и больше значение межгрупповой дисперсии, тем лучше признак характеризует принадлежность объектов к кластеру и тем «качественнее» кластеризация. Параметры F и p также характеризуют вклад признака в разделение объекта на группы. Лучшей кластеризации соответствуют большие значение первого и меньшие значения второго параметра.
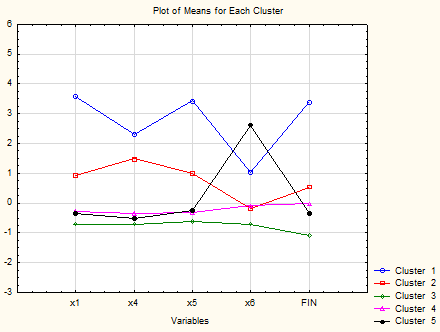
Рисунок 3 – Метод k-средних. Средние значения 5кластеров
В нашем случае можно говорить о «хорошей» кластеризации исходных данных. Кластер №1 содержит регионы с очень высоким финансово-экономическим состоянием отрасли. Кластер №2 содержит регионы с высоким финансово-экономическим состоянием отрасли. Кластер №3 содержит регионы с низким финансово-экономическим состоянием отрасли. Кластер №4 и №5 содержит регионы с средним финансово-экономическим состоянием отрасли, наблюдается различие между кластерами по фактору x6 (внесение удобрений), что может говорить о географических особенностях регионов, попавших в кластер №5.
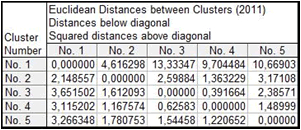
Рисунок 4 – Расстояние между кластерами (5 кластеров)
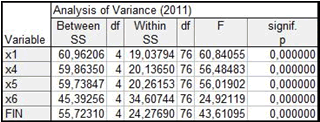
Рисунок 5 – Анализ дисперсий (5 кластеров)
В таблице 1 представлено распределение регионов по кластерам
Таблица 1 – Кластеризация. Метод k-средних
| Кластер | |||||
|
Регион |
№1 | №2 | №3 | №4 | №5 |
| Кра23 | Белго | Ивано | Брянс, Влади | Липец | |
| Росто | Ворон | Архан | Калуж, Костр | Калин | |
| Ставр | Курск | Ненец | Моско, Орлов | Ленин | |
| Тамбо | Псков | Рязан, Смоле | Мурма | ||
| Волго | Ингуш | Тверс, Тульс | Сахал | ||
| Башко | Чечен | Яросл, Карел | |||
| Татар | Ханты | Коми, Волог | |||
| Оренб | Ямало | Новго, Адыге | |||
| Сарат | Тыва | Калмы, Астра | |||
| Челяб | Забай | Дагес, Кабар | |||
| Алт.кр | Томск | Карач, Осети | |||
| Кра24 | Саха | Марий, Мордо | |||
| Новос | Хабар | Удмур, Чуваш | |||
| Омска | Чукот | Пермс, Киров | |||
| Нижег, Пензе | |||||
| Самар, Ульян | |||||
| Курга, Сверд | |||||
| Тюмен, р.Алтай | |||||
| Бурят, Хакас | |||||
| Иркут, Кемер | |||||
| Камча, Примо | |||||
| Амурс, Магад, Еврей | |||||
| Всего | 3 | 14 | 14 | 22 | 5 |
Используем алгоритм нечеткой кластеризации (fuzzy c-means) и сравним полученные результаты. Главным достоинством данного метода является использование понятия нечеткости при определении принадлежности к определенному кластеру. Таким образом, элемент может принадлежать к каждому кластеру с определенной степенью принадлежности от 0 до 1. Используя прикладную программу Matlab и fuzzy logic toolbox [5], проведем нечеткую кластеризацию методом c-средних (команда fcm). В качестве параметров минимизирующей функции возьмем параметры, предлагаемые по умолчанию. Средние значения для каждого полученного кластера (центр кластера) представлены на рисунке 6 на линейном графике.
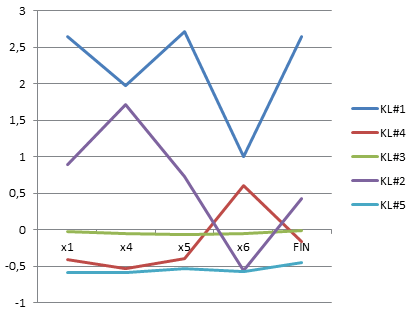
Рисунок 6 – Метод fuzzy c-means. Средние значения 5кластеров.
Проанализировав матрицу принадлежности регионов к конкретному кластеру, получаем следующий результат (таблица 2). Стоит отметить, что алгоритм нечеткой кластеризации, используя понятия нечеткости, сумел лучше выделить кластеры и более «равномерно» распределил объекты наблюдений. В случае если регион с одинаковой степенью принадлежности относится сразу к нескольким кластерам, то мы использовали результаты первого метода.
Таблица 2 – Кластеризация. Метод fuzzy c-means
|
Кластер |
|||||
|
1 |
2 |
3 |
4 |
5 |
|
|
Регион |
Ворон |
Белго |
Брянс |
Влади |
Ивано |
|
Кра23 |
Курск |
Моско |
Калуж |
Костр, Смоле |
|
|
Росто |
Тамбо |
Орлов |
Липец |
Тверс, Яросл |
|
|
Ставр |
Волго |
Рязан |
Тульс |
Архан, Ненец |
|
|
Башко |
Кабар |
Карел |
Псков, Калмы |
||
|
Татар |
Мордо |
Коми |
Дагес, Ингуш |
||
|
Оренб |
Удмур, Чуваш |
Волог |
Осети, Чечен |
||
|
Сарат |
Пермс, Киров |
Калин |
Марий, Ханты |
||
|
Челяб |
Нижег, Тюмен |
Ленин, Камча |
Ямало, Алтай |
||
|
Алтай |
Пензе, Кра24 |
Мурма, Карач |
Бурят, Тыва |
||
|
Новос |
Самар, Кемер |
Новго, Магад |
Хакас, Забай |
||
|
Омска |
Ульян, Амурс |
Адыге, Сахал |
Саха , Хабар |
||
|
Курга, Сверд |
Астра, Примо |
Еврей, Чукот |
|||
|
Всего |
4 |
12 |
20 |
18 |
27 |
Заключение. В ходе исследования нами были достигнуты следующие результаты: выполнен анализ состояния отрасли растениеводства регионах России, разработан комплекс статистических показателей оценки состояния отрасли в регионах, проведен корреляционный, факторный анализ показателей. Проведена кластеризация регионов по выделенным факторам двумя методами. Таким образом, используя результаты кластерного анализа, мы подтвердили гипотезу о существовании пяти кластеров регионов РФ в отрасли растениеводство:
- кластер №1 – содержит в себе группу регионов с очень высоким финансово-экономическим состоянием отрасли растениеводство (4 региона);
- кластер №2 – содержит в себе группу регионов с высоким финансово-экономическим состоянием отрасли растениеводство (12 регионов);
- кластер №3 – содержит в себе группу регионов со средним финансово-экономическим состоянием отрасли растениеводство (20 регионов);
- кластер №4 – содержит в себе группу регионов с «низким финансово-экономическим состоянием отрасли растениеводство (18 регионов);
- кластер №5 – содержит в себе группу регионов с «очень низким финансово-экономическим состоянием отрасли растениеводство (21 регион).
В дальнейшем, опираясь на результаты кластерного анализа и экспертные заключения, необходимо выполнить следующий этап моделирования, связанный с разработкой дискриминантных моделей и нечеткой продукционной системы. Эти модели позволят более точно и эффективно оценивать как отрасль растениеводства в целом, так и в каждом регионе РФ.

Читайте также

Библиографический список
- Леоненков А.В. Нечёткое моделирование в среде MATLAB и fuzzyTECH. – СПб.: БХВ-Петербург, 2007. -736 с.
- Минаков И. А. Экономика отраслей АПК: учеб. — М. Колосс. 2008. — 256 с.
- Огнев Ю.Ю. Аграрный вопрос. Основные предложения. — М.: Пресс, 2010. — 56 с.
- Халафян А.А. STATISTICA 6. Статистический анализ данных. — 3-е изд. учеб. — М.: Бином-Пресс, 2007. — 512 с.
- Центральная база статистических данных // Федеральная служба государственной статистики URL: http//www.gks.ru (дата обращения: 01.04.2013).
References
- Leonenkov A.V. Fuzzy modeling in MATLAB and fuzzyTECH [Nechetkoe modelirovanie v srede MATLAB i fuzzyTECH]. – St. Petersburg.: BHV-Petersburg, 2007. 736 p.
- Minakov I. A. Economy agricultural industries: textbook [Ekonomika otraslei APK]. M.: Colossus. 2008. 256 p.
- Ognev Iu.Iu. The agrarian question. The main proposals [Agrarnyi vopros. Osnovnye predlozheniia]. M.: Press, 2010. 56 p.
- Khalafian A.A. STATISTICA 6. Statistical analysis [STATISTICA 6. Statisticheskii analiz dannykh]. 3rd ed. textbook. M.: Bean-Press, 2007. 512 p.
- The central statistical database [Tcentralnaia baza statisticheskikh dannykh]. Federal State Statistics Service URL: http//www.gks.ru (date accessed: 01.04.2013).

