Рынок жилья: методы моделирования и оценки состояния
The housing market: modeling and assessment methods

Авторы
Аннотация
В работе проанализированы теоретические основы эконометрического моделирования – модели, которые могут быть использованы для исследования жилищной сферы. Показаны методы практического использования корреляционных и регрессионных моделей при анализе состояния и перспективах развития рынка жилья.
Ключевые слова
Рынок жилья, жилищная сфера, эконометрика, эконометрические методы, модель, корреляция, регрессия, моделирование.
Рекомендуемая ссылка
Аксёнова Ирина Александровна, Западнюк Евгений Александрович. Рынок жилья: методы моделирования и оценки состояния // Современные технологии управления. ISSN 2226-9339. — №10 (70). Номер статьи: 7003. Дата публикации: 31.10.2016. Режим доступа: https://sovman.ru/article/7003/
Authors
Abstract
This paper analyzes the theoretical foundations of econometric simulation model that can be used to study the housing sector. Shows the methods of the practical use of correlation and regression models in the analysis of the status and prospects of development of the housing market.
Keywords
The housing market, the housing sector, econometrics, econometric methods, model, correlation, regression, modeling.
Suggested citation
Aksjonova Irina Aleksandrovna, Zapadnjuk Evgenij Aleksandrovich. The housing market: modeling and assessment methods // Modern Management Technology. ISSN 2226-9339. — №10 (70). Art. # 7003. Date issued: 31.10.2016. Available at: https://sovman.ru/article/7003/
Введение
Одним из основных методов исследования экономических явлений и процессов является основанный на принципе аналогии метод моделирования.
Необходимость использования этого метода в целом определяется тем, что многие объекты (или проблемы, относящиеся к этим объектам) непосредственно исследовать или вовсе невозможно, или же это исследование требует слишком высоких затрат времени и средств.
Такая ситуация проявляется и в экономической практике, где результаты деятельности во многом зависят от качества принимаемых решений. Безусловно, в привычных, повторяющихся условиях управляющие решения могут приниматься на основе накопленного опыта, интуиции или здравого смысла. Но наилучшие решения не всегда лежат на поверхности, аналогов в прошлом опыте может и не быть, а цена ошибки при современных масштабах производства очень велика. Самым надежным способом выбора эффективного решения была бы постановка экспериментов непосредственно на объекте. Однако такие эксперименты часто невозможны или затруднительны ввиду их дороговизны, длительных сроков проведения, опасности нежелательных последствий.
Как известно, основные результаты экономической теории носят качественный характер. Например, в экономической теории при формулировании закон спроса утверждается, что снижение цены товара (при неизменности всех прочих факторов) приводит к увеличению спроса на данный товар. Однако в экономической теории не указывается количественных оценок такого увеличения, то есть нет ответа на вопрос: насколько увеличится спрос при уменьшении цены товара на определенную величину. Расчет количественных характеристик только и возможно при использовании методов эконометрики. В этой связи изучение эконометрических методов и их использование в анализе экономических явлений весьма актуально. Более того, эконометрические методы позволяют построить модели взаимосвязей в экономике, количественно оценить зависимости, отражающие эти взаимосвязи, и использовать полученные оценки или для прогнозирования, или для объяснения внутренних механизмов исследуемых экономических явлений, что особенно важно на современном этапе развития экономических отношений.
Касаясь актуальности темы исследования, следует особо подчеркнуть, что эконометрические методы занимают свою нишу научных и прикладных исследований на стыке экономической теории, экономической статистики, математического моделирования, теории вероятностей и математической статистики. Связь эконометрики с отмеченными научными дисциплинами проявляется по-разному: 1) в экономической теории с помощью качественного анализа устанавливается совокупность факторов и показателей, влияющих на изучаемое экономическое явление, их роль и теоретические взаимосвязи;2) в экономической статистике обеспечивается информационная основа экономических исследований, представляются эмпирические данные выбранных экономических показателей в виде таблиц, диаграмм, графиков и обеспечивается их первичная обработка; при этом различаются пространственные данные (взятые по разным объектам за один и тот же период или момент времени) и временные данные (рассматриваемые для одного экономического объекта в последовательные моменты времени); 3) в математическом моделировании формализуется экономическая задача на языке математики; 4) для исследования построенных экономико-математических моделей в эконометрике используется специфический математический аппарат, опирающийся на теорию вероятностей и математическую статистику.
Исследование эконометрической модели даже с небольшим числом факторов в «ручном» исполнении весьма трудоёмко. В настоящее время на помощь пришли компьютерные технологии, позволяющие значительно упростить расчет регрессионных моделей. Для этих целей используются специализированные пакеты прикладных программ, среди которых наибольшее распространение получил табличный процессор Excel. Таким образом, кроме указанных выше научных дисциплин, эконометрика тесно связана с компьютерными технологиями, используя их для автоматизации вычислений.
Цель данной работы – рассмотреть не только теоретические основы основных методов эконометрики, но и показать, как они используются при анализе состояния и функционирования рынка жилья, реализации жилищной политики государства.
В соответствии с целью были поставлены следующие задачи: 1) исследовать методологические основы эконометрического моделирования; 2) выявить особенности использования эконометрических методов исследований жилищной сферы; 3) предложить методы практической реализации корреляционных и регрессионных моделей при исследовании рынка жилья.
Предмет исследования – рынок жилья в переходной национальной экономике. Объект исследования – эконометрические методы исследования жилищной сферы жилья.
Значимость представляемой работы заключается в практической направленности работы: показано на конкретных примерах, как можно использовать, реализовать корреляционные и регрессионные модели при исследовании рынка жилья.
Эконометрические методы исследования в настоящее время в достаточной мере находят свое отражение в специализированной литературе по экономике. Но вплоть до начала 2000-х годов эконометрика была в определенной мере «забыта»: было крайне недостаточно ни переводных, ни отечественных работ. Причины понятны: в централизованной плановой экономике эконометрика не была широко востребована, в отличие, например, от балансовых или оптимизационных методов. Сегодня ситуация изменилась: эконометрические методы находят свое отражение в трудах, учебниках зарубежных и отечественных ученых: К. Доугерти, Дж. Стиглица, Ц. Грилихеса, В.Л макарова, Я.Р. Магнуса, В.М. Полтеровича, Р.С. Гринберга, Н.Ш. Кремера, П.К. Катышева, А.А. Пересецкий, Н.П. Тихомировова, , И.И. Елисеевой и др. Свой вклад в развитие эконометрики внесли и белорусские ученые: В.И. Абрамов, Т.Ф. Калмыкова, Т.М. Моисеева, С.Ф. Каморников, Л.П. Зенькова, О.В. Пугачёва, С.С. Сакович и др.
Однако несмотря на значительное количество публикаций по тематике эконометрических методов, ряд вопросов практического их использования требуют своей разработки.
1. Теоретические основы эконометрических моделей и их типы
1.1. Методологические основы эконометрического моделирования
Для построения и анализа эконометрических моделей используется специфический статистический и математический аппарат. В частности, для установления тесноты связи между переменными регрессионной модели используется корреляционный анализ.
Корреляция (от латинского слова correlatio – взаимозависимость) в широком смысле слова означает связь между явлениями и процессами, а корреляционный анализ позволяет оценить силу, или тесноту, этой связи, используя понятия ковариации и корреляции.
Поэтому основными задачами корреляционного анализа являются:
- количественное измерение степени зависимости переменных;
- отбор факторов, оказывающих наибольшее влияние на результативный признак;
- обнаружение неизвестных причинных связей.
Что касается последнего, то с помощью только корреляционного анализа нельзя указать, какую переменную следует принимать в качестве причины, а какую – в качестве следствия. Для выявления причинной взаимообусловленности, количественные оценки взаимосвязей, полученные с помощью корреляционного анализа, должны быть обязательно дополнены глубоким анализом сущности изучаемого явления на базе экономической теории.
Корреляционный анализ существенно связан с методами регрессионного анализа, которые направлены на установление формы зависимости между переменными (то есть формы функции ![]() ) и оценку параметров функции регрессии (то есть на выделение из некоторого множества функций той функции, которая дает наилучшее приближение к исходным данным).
) и оценку параметров функции регрессии (то есть на выделение из некоторого множества функций той функции, которая дает наилучшее приближение к исходным данным).
Таким образом, основными задачами регрессионного анализа являются:
- определение вида уравнения регрессии по имеющимся данным наблюдений (спецификация модели);
- оценка параметров уравнения по реальным данным (параметризация модели);
- анализ качества уравнения, проверка адекватности уравнения эмпирическим данным, улучшение качества уравнения (верификация модели).
Термин «регрессия» (от латинского слова regressio – движение назад, возврат в прежнее состояние) ввел английский статистик Френсис Гальтон в конце XIX века при анализе влияния роста родителей и более отдаленных предков на рост детей. Гальтон заметил, в частности, что рост детей у высоких родителей в среднем меньше среднего роста родителей, а у низких родителей наблюдается обратная закономерность. Таким образом, осуществляется возврат среднего роста детей аномальных родителей к среднему росту людей в данном регионе. Кроме того, по его модели рост ребенка определяется наполовину родителями, на четверть – родителями родителей и т.д. Другими словами, модель Гальтона характеризует движение назад по генеалогическому дереву. Эти наблюдения и были положены в основу выбора терминологии. В настоящее время термин «регрессия», конечно, не отражает всей сущности регрессионного метода, но продолжает использоваться для описания статистической связи между случайными величинами.
Следует еще отметить, что какой бы хорошо подогнанной и математически обоснованной не была модель, ее главное содержание определяется экономической теорией, а результат моделирования представляет интерес только в том случае, когда он имеет экономическую интерпретацию.
1.2. Эконометрические исследования жилищной сферы
Рассмотрим возможности эконометрического на примере рынка жилья. Предположим, что некоторая риэлтерская фирма желает составить для себя точное представление об ожидаемой цене на квартиры.
Первый шаг такого исследования состоит в том, чтобы установить факторы, определяющие цену p, которая выступает в данном примере в качестве результирующего фактора и является зависимой (или, иначе, объясняемой) переменной. Конечно, значение цены квартиры зависит практически от бесконечного количества факторов. К ним относятся, например, площадь квартиры, количество ее комнат, площадь кухни, совмещенность или несовмещенность санузла, этажность дома, номер этажа, на котором расположена квартира, удаленность квартиры от центра города, наличие квартир на вторичном рынке жилья и новых квартир и многие-многие другие. Выберем лишь те, которые оказывают наиболее существенное влияние на цену p. Отнесем к ним площадь квартиры s и удаленность ее от центра города l. Эти величины называются независимыми (или объясняющими) факторами (их еще называют регрессорами). Доля влияния остальных факторов незначительна, их игнорирование в среднем не приведет к существенным отклонениям цены p. Поэтому все они рассматриваются как одна случайная переменная ε (она называется возмущением или ошибкой). В результате зависимость переменной p разбивается на две части – зависимость объясненную (связанную с переменными s и l) и случайную ε.
Отметим, что фирма располагает данными по n квартирам города, причем для каждой из них известны площадь s1, s2, …, sn, удаленность от центра города l1, l2, …, ln и цена p1, p2, …, pn .
Второй шаг исследования состоит в построении эконометрической модели. Речь идет о том, чтобы на основании имеющихся статистических данных определить объясненную часть переменной p, рассматривая случайную составляющую как случайную величину, подобрать функцию f(s,l) так, чтобы она наиболее точно соответствовала статистическим данным. При такой постановке задачи эконометрическая модель имеет вид, схематически изображенный на рисунке 1.

Рисунок 1 – Эконометрическая модель задачи
Вполне понятно, что стоимость квартиры тем больше, чем больше ее площадь, и тем меньше, чем дальше она расположена от центра города. Это означает, что между переменными p и s существует прямая зависимость, а между p и l – обратная. Поэтому в качестве общей формулы можно взять, например, формулу
![]() (1.1)
(1.1)
Тогда эконометрическая модель задается уравнением
![]() , (1.2)
, (1.2)
где p – цена квартиры; s – площадь квартиры; l – расстояние до центра города.
После спецификации модели решение задачи вступает в этап параметризации. На этом этапе необходимо подобрать параметры a и b таким образом, чтобы при подстановке в формулу (2.1) значений si ,li получались значения, расположенные в среднем как можно ближе к значениям pi (i = 1, 2, …, n).
Отметим, что успех математического моделирования во многом зависит от спецификации модели. Поэтому эконометрист построит разные модели, а потом из них выберет наилучшую.
Поясним еще один момент, касающийся практических целей эконометрического моделирования. Предположим, что параметризованная на основании равенства (1.2) эконометрическая модель имеет вид:
![]() . (1.3)
. (1.3)
Тогда, опираясь на модель (1.3), в частности, можно:
а) спрогнозировать цену квартиры (например, квартира площадью в 40 м2, расположенная в двух км от центра города, предположительно будет стоить ![]() денежных единиц);
денежных единиц);
б) оценить целесообразность (существенность) факторов s и l;
в) выявить влияние на цену квартиры каждого фактора;
г) получить статистические доказательства надежности выводов а)-в).
Теперь риэлтор может легко определить ожидаемую цену любой квартиры, даже если ее аналогов нет в базе данных фирмы. В этом и состоит главное практическое приложение полученного результата.
2. Практическая реализация корреляционных и регрессионных моделей при исследовании рынка жилья
Рассмотрим на конкретных примерах использование корреляционных и регрессионных моделей при исследовании рынка жилья в Республике Беларусь.
1. По статистическим данным, приведенным в таблице 1, построим корреляционное поле зависимости спроса y на 1 квадратный метр жилья от его цены x и определим форму связи между результирующим признаком y и фактором x.
Таблица 1 – Статистические данные примера 1
| Цена 1 кв. м жилья, у.е. (Р) | Спрос на жилую площадь (D) |
| 99 | 100 |
| 82 | 115 |
| 77 | 210 |
| 69 | 270 |
| 52 | 323 |
| 44 | 478 |
| 31 | 544 |
| 29 | 564 |
| 28 | 570 |
Построим модель. Из вида корреляционного поля (рисунок 2) можно сделать вывод о том, что между результирующим признаком y и фактором x существует обратная зависимость, то есть с ростом цены спрос на жилую площадь уменьшается. Такое поведение спроса в зависимости от цены согласуется с выводами экономической теории. Можно предположить также, что форма связи между результирующим признаком y и фактором x является линейной.
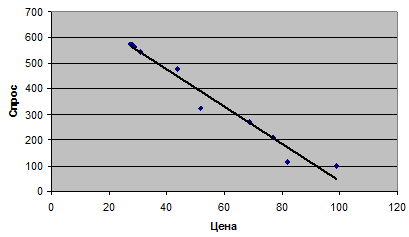
Рисунок 2 – Корреляционное поле статистической зависимости D и P
Второй пример. В таблице 2 представлена информация по семи территориям определенного региона о значениях процентной доли расходов на жильё в общих расходах (y) и значениях среднедневной заработной платы одного работающего (x).
Таблица 2 – Статистические данные по второму примеру
| Расходы на покупку жилья в общих расходах
(в процентах, y) |
Среднедневная заработная плата одного работающего
(в денежных единицах, x) |
| 68,8 | 45,1 |
| 61,2 | 59,0 |
| 59,9 | 57,2 |
| 56,7 | 61,8 |
| 55,0 | 58,8 |
| 54,3 | 47,2 |
| 49,3 | 55,2 |
Для характеристики зависимости у от х рассчитаем параметры следующих регрессий:
а) линейной;
б) степенной;
в) показательной;
г) гиперболической.
Оценим каждую модель через среднюю ошибку аппроксимации Ā, индекс корреляции ρxy и F-критерий Фишера.
Построим модель:
1а) Для расчета параметров a и b линейной модели y=a+bx+ε решаем систему уравнений относительно a и b.
Соответствующие вычисления сведем в таблицу 3.
Таблица 3 – Вычисление параметров a и b
| x | y | xy | x2 | y2 | ||||
| 1 | 68,8 | 45,1 | 3102,88 | 2034,01 | 4733,44 | 61,3 | 7,5 | 10,9 |
| 2 | 61,2 | 59,0 | 3610,80 | 3481,00 | 3745,44 | 56,5 | 4,7 | 7,7 |
| 3 | 59,9 | 57,2 | 3426,28 | 3271,84 | 3588,01 | 57,1 | 2,8 | 4,7 |
| 4 | 56,7 | 61,8 | 3504,06 | 3819,24 | 3214,89 | 55,5 | 1,2 | 2,1 |
| 5 | 55,0 | 58,8 | 3234,00 | 3457,44 | 3025,00 | 56,5 | -1,5 | 2,7 |
| 6 | 54,3 | 47,2 | 2562,96 | 2227,84 | 2948,49 | 60,5 | -6,2 | 11,4 |
| 7 | 49,3 | 55,2 | 2721,36 | 3047,04 | 2430,49 | 57,8 | -8,5 | 17,2 |
| Сумма | 405,2 | 384,3 | 22162,34 | 21338,4 | 23685,76 | 405,2 | 0,0 | 56,7 |
| Среднее | 57,89 | 54,90 | 3166,05 | 3048,34 | 3383,68 | — | — | 8,1 |
| σ | 5,74 | 5,86 | — | — | — | — | — | — |
| σ2 | 32,92 | 34,34 | — | — | — | — | — | — |
Теперь по формулам находим:
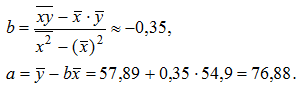
Уравнение линейной регрессии имеет вид ![]() . С увеличением среднедневной заработной платы на одну денежную единицу доля расхода на покупку жилья снижается в среднем на 0,35 %-ных пункта. Рассчитаем линейный коэффициент парной корреляции:
. С увеличением среднедневной заработной платы на одну денежную единицу доля расхода на покупку жилья снижается в среднем на 0,35 %-ных пункта. Рассчитаем линейный коэффициент парной корреляции:
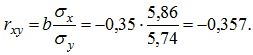
Связь умеренная, обратная.
Определим коэффициент детерминации: ![]() .
.
Изменения результата на 12,7% объясняются влиянием фактора x.
Подставляя в уравнение регрессии фактические значения x, определим теоретические (расчетные) значения ![]() . Найдем величину средней ошибки аппроксимации Ā:
. Найдем величину средней ошибки аппроксимации Ā:
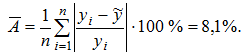
В среднем расчетные значения отклоняются от фактических на 8,1%.
Рассчитываем наблюдаемое значение F-критерия: ![]() . По таблице значений F-критерия при уровне значимости α=0,05 находим Fкр=6,61. Так как Fкр > Fнабл, то следует принять гипотезу H0 о случайной природе выявленной зависимости и статистической незначимости параметров уравнения и показателя тесноты связи.
. По таблице значений F-критерия при уровне значимости α=0,05 находим Fкр=6,61. Так как Fкр > Fнабл, то следует принять гипотезу H0 о случайной природе выявленной зависимости и статистической незначимости параметров уравнения и показателя тесноты связи.
1б) Построению уравнения ![]() степенной регрессии предшествует процедура линеаризации переменных. В данном примере линеаризация производится путем логарифмирования обеих частей уравнения:
степенной регрессии предшествует процедура линеаризации переменных. В данном примере линеаризация производится путем логарифмирования обеих частей уравнения:
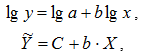
где Y = lg y, X = lg x, C = lg a.
Все расчеты сведем в таблицу 4.
Рассчитаем c и b:
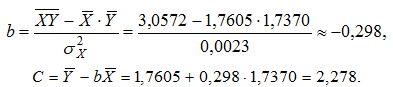
Получим линейное уравнение ![]() .
.
Выполнив его потенцирование, получим уравнение регрессии: ![]() .
.
Таблица 4 – Вычисление параметров c и b
| Y | X | XY | X2 | |
|
( |
|
|
| 1 | 1,8376 | 1,6542 | 3,0398 | 2,7364 | 61,0 | 7,8 | 60,8 | 11,3 |
| 2 | 1,7868 | 1,7709 | 3,1642 | 3,1361 | 56,3 | 4,9 | 24,0 | 8,0 |
| 3 | 1,7774 | 1,7574 | 3,1236 | 3,0885 | 56,8 | 3,1 | 9,6 | 5,2 |
| 4 | 1,7536 | 1,7910 | 3,1407 | 3,2077 | 55,5 | 1,2 | 1,4 | 2,1 |
| 5 | 1,7404 | 1,7694 | 3,0795 | 3,1308 | 56,3 | -1,3 | 1,7 | 2,4 |
| 6 | 1,7348 | 1,6739 | 2,9039 | 2,8019 | 60,2 | -5,9 | 34,8 | 10,9 |
| 7 | 1,6928 | 1,7419 | 2,9487 | 3,0342 | 57,4 | -8,1 | 65,6 | 16,4 |
| Сумма | 12,3234 | 12,1587 | 21,4003 | 21,1355 | 403,5 | 1,7 | 197,9 | 56,3 |
| Среднее | 1,7605 | 1,7370 | 3,0572 | 3,0194 | — | — | 28,27 | 8,0 |
| σ | 0,0425 | 0,0484 | — | — | — | — | — | — |
| σ2 | 0,0018 | 0,0023 | — | — | — | — | — | — |
Подставляя в данное уравнение фактические значения х, получаем теоретические значения результата ![]() . По ним рассчитываем показатели тесноты связи: индекс корреляции ρxy и среднюю ошибку аппроксимации Ā:
. По ним рассчитываем показатели тесноты связи: индекс корреляции ρxy и среднюю ошибку аппроксимации Ā:
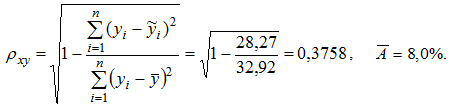
Значения показателей ρxy и Ā степенной модели указывают, что она несколько лучше линейной регрессии описывает взаимосвязь.
1в) Построению уравнения показательной регрессии ![]() предшествует процедура линеаризации путем логарифмирования обеих частей уравнения:
предшествует процедура линеаризации путем логарифмирования обеих частей уравнения:
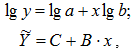
где Y = lg y, C = lg a, B= lg b.
Все расчеты сведем в таблицу 5.
Вычислим значения параметров регрессии A и B:
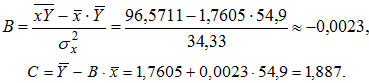
Полученное линейное уравнение принимает вид ![]() .
.
Произведем потенцирование полученного уравнения, получим уравнение регрессии: ![]() .
.
Таблица 5 – Вычисление параметров C и B
| Y | x | xY | x2 | |
|
( |
|
|
| 1 | 1,8376 | 45,1 | 82,8758 | 2034,01 | 60,7 | 8,1 | 65,61 | 11,8 |
| 2 | 1,7868 | 59,0 | 105,4212 | 3481,00 | 56,4 | 4,8 | 23,04 | 7,8 |
| 3 | 1,7774 | 57,2 | 101,6673 | 3271,84 | 56,9 | 3,0 | 9,00 | 5,0 |
| 4 | 1,7536 | 61,8 | 108,3725 | 3819,24 | 55,5 | 1,2 | 1,44 | 2,1 |
| 5 | 1,7404 | 58,8 | 102,3355 | 3457,44 | 56,4 | -1,4 | 1,96 | 2,5 |
| 6 | 1,7348 | 47,2 | 81,8826 | 2227,84 | 60,0 | -5,7 | 32,49 | 10,5 |
| 7 | 1,6928 | 55,2 | 93,4426 | 3047,04 | 57,5 | -8,2 | 67,24 | 16,6 |
| Сумма | 12,3234 | 384,3 | 675,9974 | 21338,4 | 403,0 | -1,8 | 200,78 | 56,3 |
| Среднее | 1,7605 | 54,9 | 96,5711 | 3048,34 | — | — | 28,68 | 8,0 |
| σ | 0,0425 | 5,86 | — | — | — | — | — | — |
| σ2 | 0,0018 | 34,33 | — | — | — | — | — | — |
Тесноту связи оценим через индекс корреляции ρxy:
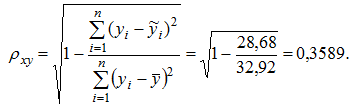
Связь умеренная. Средняя ошибка аппроксимации в допустимых пределах: Ā=8,0%. Показательная функция чуть хуже, чем степенная, описывает изучаемую зависимость.
1г) Уравнение гиперболической регрессии ![]() линеаризуется заменой
линеаризуется заменой ![]() . Тогда
. Тогда ![]() .
.
Все расчеты сведем в таблицу 6.
Вычислим значения параметров регрессии a и b:
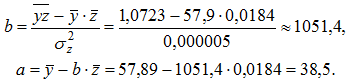
Получим уравнение регрессии ![]() . Вычислим индекс корреляции
. Вычислим индекс корреляции 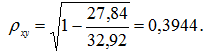
Таблица 6 – Вычисление параметров a и b
| y | z | yz | z2 | |
|
( |
|
|
| 1 | 68,8 | 0,0222 | 1,5255 | 0.000492 | 61,8 | 7,0 | 49,00 | 10,2 |
| 2 | 61,2 | 0,0169 | 1,0373 | 0.000287 | 56,3 | 4,9 | 24,01 | 8,0 |
| 3 | 59,9 | 0,0175 | 1,0472 | 0,000306 | 56,9 | 3,0 | 9,00 | 5,0 |
| 4 | 56,7 | 0,0162 | 0,9175 | 0,000262 | 55,5 | 1,2 | 1,44 | 2,1 |
| 5 | 55 | 0,0170 | 0,9354 | 0,000289 | 56,4 | -1,4 | 1,96 | 2,5 |
| 6 | 54,3 | 0,0212 | 1,1504 | 0,000449 | 60,8 | -6,5 | 42,25 | 12,0 |
| 7 | 49,3 | 0,0181 | 0,8931 | 0,000328 | 57,5 | -8,2 | 67,24 | 16,6 |
| Сумма | 405,2 | 0,1291 | 7,5064 | 0,002413 | 405,2 | 0,0 | 194,90 | 56,5 |
| Среднее | 57,9 | 0,0184 | 1,0723 | 0,000345 | — | — | 27,84 | 8,1 |
| σ | 5,74 | 0,002145 | — | — | — | — | — | — |
| σ2 | 32,9476 | 0,000005 | — | — | — | — | — | — |
Средняя ошибка аппроксимации в допустимых пределах: Ā=8,1%. Для гиперболического уравнения регрессии получена наибольшая оценка тесноты связи ρxy = 0,3944(по сравнению с линейной, степенной и показательной регрессиями).
Для гиперболической регрессии вычислим наблюдаемое значения критерия Фишера:
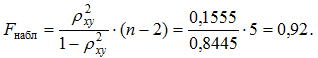
Тогда при α = 0,05 имеем, что Fкр = 6,61 > Fнабл. Следовательно, принимается гипотеза H0 о статистически незначимых параметрах уравнения гиперболической регрессии. Поэтому общее качество и этой модели следует признать невысоким.
Полученные результаты можно объяснить сравнительно невысокой теснотой зависимости между результирующим признаком y и фактором x, а также небольшим числом наблюдений (n=7).
Третий пример. По данным таблицы 7 построим линейное уравнение регрессии, отражающее зависимость стоимости квартиры от ее жилой площади.
Для построенного уравнения вычислим:
1) коэффициент корреляции,
2) коэффициент детерминации;
3) наблюдаемое значение критерия Фишера;
4) стандартные ошибки коэффициентов регрессии;
5) доверительные интервалы коэффициентов регрессии.
Осуществим точечный и интервальный прогнозы по построенной модели в случае, когда площадь квартиры составляет 41 кв. м.
Таблица 7 – Статистические данные примера
| № п/п | Стоимость (доллары) | Жилая площадь (кв. м.) |
| 1 | 5000 | 30,2 |
| 2 | 5200 | 32 |
| 3 | 5350 | 32 |
| 4 | 5880 | 37 |
| 5 | 5430 | 30 |
| 6 | 5430 | 30 |
| 7 | 5430 | 30 |
| 8 | 5350 | 29 |
| 9 | 5740 | 33 |
| 10 | 5570 | 31 |
| 11 | 5530 | 30 |
| 12 | 6020 | 34 |
| 13 | 7010 | 38 |
| 14 | 6420 | 31 |
| 15 | 7150 | 39 |
| 16 | 7190 | 39,5 |
По формулам ![]() находим коэффициенты регрессии: b = 170,239, a = 262,847 . Поэтому построенная линейная модель имеет вид
находим коэффициенты регрессии: b = 170,239, a = 262,847 . Поэтому построенная линейная модель имеет вид ![]() .
.
Коэффициент регрессии b модели показывает, что в среднем увеличение жилой площади квартиры на 1 кв. метр приводит к увеличению ее стоимости на 170,24 доллара США.
Расчет линейного коэффициента корреляции и коэффициента детерминации дает ![]() . Связь между факторами является высокой, поэтому стоимость квартиры существенно зависит от ее жилой площади. Величина
. Связь между факторами является высокой, поэтому стоимость квартиры существенно зависит от ее жилой площади. Величина ![]() показывает, что изменения стоимости квартиры на 72,81% объясняется размером жилой площади.
показывает, что изменения стоимости квартиры на 72,81% объясняется размером жилой площади.
Расчет дисперсионного отношения Фишера дает значение ![]() . Сравнивая наблюдаемое значение F-критерия Фишера с критическим Fкр = 4,60 при α = 0,05, получаем, что Fкр < Fнабл . Таким образом, уравнение регрессии значимо и построенная модель адекватна выборочным данным.
. Сравнивая наблюдаемое значение F-критерия Фишера с критическим Fкр = 4,60 при α = 0,05, получаем, что Fкр < Fнабл . Таким образом, уравнение регрессии значимо и построенная модель адекватна выборочным данным.
Расчет стандартных ошибок коэффициентов регрессии осуществляется по формулам (3.4). В нашем случае имеем ma = 918,35 , mb = 27,79.
Доверительные интервалы для каждого коэффициента регрессии имеют вид: ![]() . Зная точечные оценки коэффициентов регрессии, их стандартные ошибки и критическое значение t-статистики Стьюдента tкр = 2,1448, находим, что
. Зная точечные оценки коэффициентов регрессии, их стандартные ошибки и критическое значение t-статистики Стьюдента tкр = 2,1448, находим, что ![]() .
.
Для вычисления точечного прогноза подставим значение xp=41 в полученное уравнение линейной регрессии ![]() . Получим:
. Получим: ![]() . Таким образом, прогнозируемая по построенной модели стоимость квартиры площадью 41 квадратный метр составляет 7242,65 доллара США.
. Таким образом, прогнозируемая по построенной модели стоимость квартиры площадью 41 квадратный метр составляет 7242,65 доллара США.
Для построения доверительного интервала прогноза вычислим стандартную ошибку прогноза mp по формуле 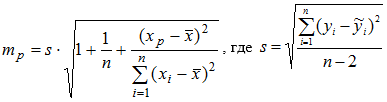 – стандартная ошибка регрессии. В нашем случае s = 382,9. Поэтому
– стандартная ошибка регрессии. В нашем случае s = 382,9. Поэтому 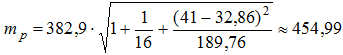 . Теперь нижняя и верхняя границы интервала прогноза при α = 0,05 и tкр = 2,1448 определяются по формулам
. Теперь нижняя и верхняя границы интервала прогноза при α = 0,05 и tкр = 2,1448 определяются по формулам ![]() и
и ![]() . Окончательно находим, что доверительный интервал прогноза стоимости квартиры имеет вид
. Окончательно находим, что доверительный интервал прогноза стоимости квартиры имеет вид ![]() . Таким образом, значение цены квартиры площадью 41 квадратный метр с вероятностью 0,95 находится в пределах от 6266,78 до 8218,51 доллара.
. Таким образом, значение цены квартиры площадью 41 квадратный метр с вероятностью 0,95 находится в пределах от 6266,78 до 8218,51 доллара.
Расчет и анализ показателей парной линейной регрессии может быть осуществлен с помощью «Пакета анализа» табличного процессора Excel. Основную информацию о линейной модели дает программа «Регрессия». Эта информация содержится в четырех таблицах: «Регрессионная статистика», «Дисперсионный анализ» (две таблицы) и «Вывод остатка».
В таблице «Регрессионная статистика» приводятся значения:
- Множественный R – линейный коэффициент корреляции rxy.
- R-квадрат – коэффициент детерминации R2.
- Нормированный R2 – скорректированный R2 с поправкой на число степеней свободы.
- Стандартная ошибка – стандартная ошибка регрессии s.
- Наблюдения – число наблюдений n.
В первой таблице «Дисперсионный анализ» приведены:
- Столбец df – число степеней свободы, равное:
df = 1 для строки Регрессия;
df = n — 1 для строки Остаток;
df = n — 1 для строки Итого.
- Столбец SS – сумма квадратов отклонений, равная:
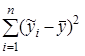 для строки Регрессия;
для строки Регрессия;
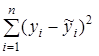 для строки Остаток;
для строки Остаток;
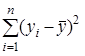 для строки Итого.
для строки Итого.
- Столбец MS – дисперсии, определяемые по формуле
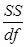 :
:
факторная для строки Регрессия;
остаточная для строки Остаток.
- Столбец F – наблюдаемое значение F-критерия Фишера Fнабл.
- Столбец Значимость F – значение уровня значимости, соответствующее вычисленной F-статистике.
Если значимость F меньше заданного уровня значимости α, то R2 статистически значим.
Во второй таблице «Дисперсионный анализ» указаны:
- Коэффициенты – значения коэффициентов а и b.
- Стандартная ошибка – стандартные ошибки коэффициентов регрессии а и b.
- t-статистика – наблюдаемые значения t-статистики tнабл для коэффициентов регрессии а и b.
- P-Значение – значение уровня значимости, соответствующее вычисленной t-статистике.
Если P-значение меньше заданного уровня значимости , то соответствующий коэффициент регрессии статистически значим.
- Нижние 95% и Верхние 95% – нижние и верхние границы 95%-ных доверительных интервалов для коэффициентов уравнения линейной регрессии.
В таблице «Вывод остатка» указаны:
- Наблюдение – номер наблюдения.
- Предсказанное – расчетные (теоретические) значения
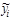 .
. - Остатки – разность
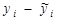 между наблюдаемыми и расчетными значениями зависимой переменной.
между наблюдаемыми и расчетными значениями зависимой переменной.
Методику вычисления ключевых показателей парной линейной регрессии проиллюстрируем на примере следующей задачи (при этом будем опираться на статистические данные, находящиеся в таблице 7, и исходить из того, что объем выборки n равен 20).
Решим задачу. Для прогноза возможного объема экспорта услуг по строительству жилья на основе ВНП построим и исследуем парную линейную регрессионную модель ![]() зависимости объема экспорта услуг по строительству жилья (y, усл. ед.) от ВНП (x, усл. ед.) Используем построенную модель для прогноза при xp=2500.
зависимости объема экспорта услуг по строительству жилья (y, усл. ед.) от ВНП (x, усл. ед.) Используем построенную модель для прогноза при xp=2500.
Что необходимо для этого сделать:
1) ввести данные;
2) построить корреляционное поле зависимости экспорта y от ВНП x;
3) установить тесноту и вид связи между указанными показателями, то есть рассчитать ковариацию и корреляцию и проанализировать их;
4) найти точечные и интервальные оценки для коэффициентов регрессии a и b;
5) оценить коэффициент детерминации и провести анализ общего качества уравнения регрессии;
6) указать стандартную ошибку регрессии;
7) оценить статистическую значимость коэффициентов регрессии a и b при уровне значимости α = 0,05, при необходимости получить новое уравнение регрессии со значимыми коэффициентами;
8) выяснить, выполняются ли условия теоремы Гаусса-Маркова; для этого оценить разброс точек на графике остатков, построить гистограмму остатков, проанализировать их числовые характеристики;
9) дать точечный и интервальный прогнозы объема экспорта по заданному значению ВНП.
Результаты вычислений и анализа оформим в виде отчета (форма отчета прилагается ниже). Для этого:
1) В ячейку А1 введём название ВНП, в ячейку В1 – название Экспорт. В ячейки А2, А3, …, А21 введем данные первого столбца выбранного варианта задания, в ячейки В2, В3, …, В21 – данные второго столбца выбранного варианта.
Присвоим листу 1 название «Исходные данные».
2) На листе «Исходные данные» выполним следующие действия:
- на панели инструментов активизируется кнопка Мастер диаграмм (шаг 1 из 4), в одноименном диалоговом окне среди стандартных типов выбирается Точечная и верхний левый вид диаграммы и нажимается кнопка Далее>;
- открывается диалоговое окно Мастер диаграмм (шаг 2 из 4), в котором во вкладке Диапазон данных в поле Диапазон вводим ссылка на диапазон ячеек A2:В21; нажимается кнопка Далее>;
- открывается диалоговое окно Мастер диаграмм (шаг 3 из 4), в котором во вкладке Заголовки в поле Ось Х (категорий) вводится название «ВНП», в поле Ось Y(значений) – название «Экспорт»; во вкладке Легенда снимается флажок. Добавляем легенду и нажимаем кнопку Далее>;
- открывается диалоговое окно Мастер диаграмм (шаг 4 из 4) в поле имеющемся устанавливается флажок и нажимается кнопка Готово.
Рисунок 3 – Диалоговое окно «Мастер диаграмм (шаг 1 из 4)»
3) В меню Сервис выбираем дополнение Анализ данных, в предложенных инструментах анализа выделяем Ковариация, нажимаем кнопку ОК. Устанавливаем значения параметров в появившемся диалоговом окне (рисунок 4) следующим образом:
Рисунок 4 – Диалоговое окно «Ковариация»
- Входной интервал – введем ссылки на ячейки А1:В21 (курсор установим в поле «Входной интервал», указатель мыши поместим в ячейку А1, удерживая нажатой левую клавишу, протянем указатель мыши до ячейки В21);
- Группирование – флажок по столбцам устанавливается автоматически;
- Метки в первой строке – устанавливаем флажок щелчком левой кнопки мышки;
- Параметры вывода – устанавливаем флажок на Новый рабочий лист, поставив курсор в поле напротив, вводим название «Ковариация».
Нажимем ОК.
Возвращеемся на лист «Исходные данные». В меню Сервис выбираем опцию Анализ данных и выделите Корреляция. Устанавливаем в диалоговом окне (рисунок 5) следующим образом значения параметров:
Рисунок 5 – Диалоговое окно «Корреляция»
- Входной интервал – вводим ссылки на ячейки, содержащие исходные данные А1:В21 (курсор устанавливаем в поле «Входной интервал», указатель мыши помещаем в ячейку А1, удерживая нажатой левую клавишу, протягиваем указатель мыши до ячейки В21);
- Группирование – устанавливаем флажок по столбцам;
- Метки в первой строке – устанавливаем флажок;
- Параметры вывода – устанавливаем флажок на Новый рабочий лист, вводим название «Корреляция».
Нажмимаем ОК.
Значение линейного коэффициента корреляции находится на листе «Корреляция» в ячейке В3.
4) Везвращаемся на лист «Исходные данные». В меню Сервис выбираем дополнение Анализ данных указываем Регрессия. Нажимаем кнопку ОК. Устанавливаем в диалоговом окне (рисунок 6) значения параметров:
- Входной интервал Y – вводим ссылки на ячейки В1:В21;
- Входной интервал X – вводим ссылки на ячейки А1:А21;
- Метки – устанавливаем флажок;
- Уровень надежности – устанавливаем флажок;
- Константа ноль – не активизируем;
- Параметры вывода – устанавливаем флажок на Новый рабочий лист и в поле напротив вводим имя «Регрессия»;
- Остатки – устанавливаем флажок;
- Стандартизованные остатки – оставляем пустым;
- График остатков – устанавливаем флажок;
- График подбора – устанавливаем флажок;
- График нормальной вероятности – оставляем пустым. Нажимаем ОК.
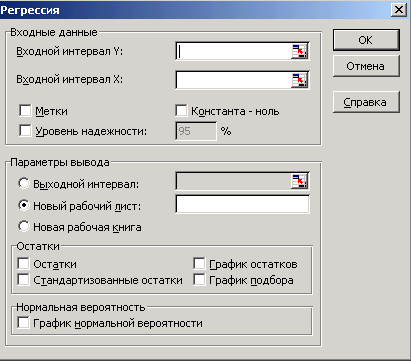
Рисунок 6 – Диалоговое окно «Регрессия»
5) Значение коэффициента детерминации R2 находится на листе «Регрессия» в ячейке В5. Наблюдаемое значение F-критерия Фишера Fнабл находится на листе «Регрессия» в ячейке E12.
Вычисляем критическое значение Fкр в свободной ячейке E15.
6) Значение стандартной ошибки регрессии s находятся на листе «Регрессия» в ячейке В7.
7) Наблюдаемые значения t-статистики tнабл коэффициентов регрессии a и b находятся на листе «Регрессия» в ячейках D17 и D18 соответственно.
Вычисляем критическое значение tкр в свободной ячейке D19.
8) На листе регрессия в меню Сервис выбираем Анализ данных, указываем Гистограмма. Нажмите кнопку ОК. Устанавливаем значения параметров в появившемся диалоговом окне (рисунок 7).
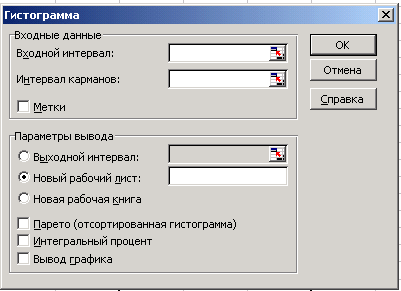
Рисунок 7 – Диалоговое окно «Гистограмма»
Возвращаемся на лист «Регрессия». Выбираем в опциях меню Сервис → Анализ данных → Описательная статистика, нажимаем ОК. Устанавливаем значения параметров в диалоговом окне (рисунок 8).
- Входной интервал – вводим ссылки на ячейки С24:С44 (столбец Остатки с названием);
- Группирование – устанавливаем флажок по столбцам;
- Метки – устанавливаем флажок в первой строке;
- Выходной диапазон – устанавливаем флажок на Новый рабочий лист и в поле напротив вводим название «Статистика остатков»;
- устанавливаем флажки Итоговая статистика, уровень надежности (95%).
Нажимаем ОК.
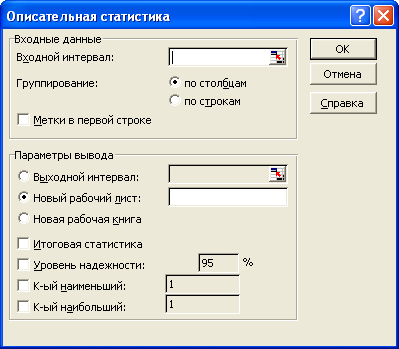
Рисунок 8 – Диалоговое окно «Описательная статистика»
9) Возвращаемся на лист «Регрессия» и в пустой ячейке E22 листа вводим формулу =В17+В18*2500 – точечный прогноз.
На листе «Регрессия» в пустой ячейке E23 вычисляем значение mp по формуле 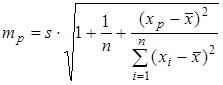 , где s – стандартная ошибка регрессии.
, где s – стандартная ошибка регрессии.
В пустых ячейках E24 и F24 вводим формулы
=E22–D19*E23 – левый конец интервала прогноза;
=E22+D19*E23 – правый конец интервала прогноза.
Вычисление выполнено.
Заключение
В современных сложных условиях экономической жизни общества решения по управлению народным хозяйством могут приниматься, безусловно, и на основе накопленного опыта, интуиции или здравого смысла. Но наилучшие решения не всегда лежат на поверхности, аналогов в прошлом опыте может и не быть, а цена ошибки при современных масштабах производства очень велика. Самым надежным способом выбора эффективного решения была бы постановка экспериментов непосредственно на объекте. Однако такие эксперименты часто невозможны или затруднительны ввиду их дороговизны, длительных сроков проведения, опасности нежелательных последствий.
В этой связи на помощь приходит эконометрика. Она в значительной степени позволяет формировать необходимые знания и умения моделирования и прогнозирования экономических реалий, построить модели взаимосвязей в экономике, количественно оценить зависимости, отражающие эти взаимосвязи, и использовать полученные оценки или для прогнозирования, или для объяснения внутренних механизмов исследуемых экономических явлений, что особенно важно на современном этапе развития экономических отношений. При эконометрическом анализе важны не только сами расчеты и обоснования показателей, но, прежде всего, те пояснения и выводы, которые показывают, что и как эти показатели характеризуют.
Особая роль эконометрики состоит в подготовке высококвалифицированных кадров в системе университетской подготовки. По сути, современное образование держится сегодня на трех «китах»: макроэкономике, микроэкономике и эконометрике. Объясняется это тем, что современные требования к уровню экономического образования предполагают наличие у специалистов-экономистов широких математических и статистических знаний, необходимых при решении задач, связанных с моделированием и количественным анализом экономических явлений и процессов.

Читайте также
Библиографический список
- Елисеева И.И. Эконометрика: учебник. – М. : Финансы и статистика, 2008.
- Бородич С.А. Эконометрика: учебное пособие. – Мн.: Новое знание, 2001.
- Кремер Н.Ш. Эконометрика: учебник для студентов вузов. – М. : ЮНИТИ-ДАНА, 2008.
- Красс М.С., Чупрынов Б.П. Математика для экономистов. – СПб. : Питер, 2008.
- Практикум по эконометрике: учебное пособие / Под редакцией И.И. Елисеевой. – М. : Финансы и статистика, 2003.
- Доугерти К. Введение в эконометрику. – М. : Финансы и статистика, 1999.
- Айвазян С.А., Иванова С.С. Эконометрика: учебное пособие. – М. : Маркет ДС, 2007.
- Магнус Я.Р., Катышев П.К., Пересецкий А.А. Эконометрика / Начальный курс: учебник. – М. : Дело, 2004.
- Тихомиров Н.П., Дорохина Е.Ю. Эконометрика: учебник. – М. : Экзамен, 2003.
- Хацкевич Г.А., Гедранович А.Б. Эконометрика: учебно-методический комплекс. – Мн.: МИУ, 2007.
- Новиков А.И. Эконометрика: учебное пособие. – М. : ИНФА-М, 2008.
- Калмыкова Т.Ф., Моисеева Т.М. Эконометрика: пособие. – Гомель : БТЭУПК, 2008.
- Каморников С.Ф., Каморников С.С. Эконометрика. – М.: Интеграция, 2015.
- Афанасьев В.Н., Юзбашев М.М. – Анализ временных рядов и прогнозирование. – М. : Финансы и статистика, 2001.
- Кремер Н.Ш. Теория вероятностей и математическая статистика. – М. : ЮНИТИ-ДАНА, 2000.
References
- Eliseeva I.I. Econometrics, a textbook [Jekonometrika: uchebnik]. Finance and Statistics, 2008.
- Borodich S.A. Econometrics, a tutorial [Jekonometrika, uchebnoe posobie]. Mn . New knowledge, 2001.
- Kremer N.Sh. Econometrics, a textbook for university students [Jekonometrika, uchebnik dlja studentov vuzov]. UNITY-DANA, 2008.
- Krass M.S., Chuprynov B.P. Mathematics for economists [Matematika dlja jekonomistov]. Peter 2008.
- Practice of Econometrics. Textbook [Praktikum po jekonometrike, uchebnoe posobie]. Pod redakciej I.I. Eliseevoj. Moscow. Finance and Statistics, 2003.
- Dougerti K. Introduction to Econometrics [Vvedenie v jekonometriku]. Finance and Statistics, 1999.
- Ajvazjan S.A., Ivanova S.S. Econometrics: a tutorial [Jekonometrika: uchebnoe posobie]. Market DS, 2007.
- Magnus Ja.R., Katyshev P.K., Pereseckij A.A. Econometrics. Basic, tutorial [Jekonometrika. Nachal’nyj kurs, uchebnik]. Case 2004.
- Tihomirov N.P., Dorohina E.Ju. Econometrics, a textbook [Jekonometrika: uchebnik]. Examination 2003.
- Hackevich G.A., Gedranovich A.B. Econometrics, methodical complex [Jekonometrika, uchebno-metodicheskij kompleks]. MIM 2007.
- Novikov A.I. Econometrics, a tutorial [Jekonometrika, uchebnoe posobie]. INFA-M 2008.
- Kalmykova T.F., Moiseeva T.M. Econometrics. A Handbook [Jekonometrika. posobie]. Gomel BTEUPK 2008.
- Kamornikov S.F., Kamornikov S.S. Econometrics [Jekonometrika]. Integration, 2015.
- Afanas’ev V.N., Juzbashev M.M. Time series analysis and forecasting [Analiz vremennyh rjadov i prognozirovanie]. Finance and Statistics, 2001.
- Kremer N.Sh. Theory of Probability and Mathematical Statistics [Teorija verojatnostej i matematicheskaja statistika]. UNITY-DANA 2000.

