Применение глубоких нейронных сетей для задачи идентификации цифробуквенной информации с багажных бирок в аэропорту
Application of deep neural networks for identification of alphanumeric information from baggage tags at airport

Авторы
Аннотация
Статья посвящена разработке и анализу методов идентификации динамических объектов. Для решения проблемы обнаружения багажных бирок и штрих-кодов разработана нейросеть с архитектурой SSD InceptionV2. Для решения задачи идентификации цифрово-буквенной информации рассматривается несколько подходов: Tesseract, SSD InceptionV2, OpenCV и полносвязная нейросеть. Проверена работоспособность методов на реальных изображениях.
Ключевые слова
компьютерное зрение, нейронная сеть, штрих-код, код аэропорта IATA, TensorFlow, OpenCV, Python
Финансирование
Статья подготовлена при поддержке и в рамках мероприятия DR-2020 «Международный конкурс научных работ и проектов молодых исследователей “Цифровой регион – 2020”» (Наука и образование on-line)
Рекомендуемая ссылка
No items found. Применение глубоких нейронных сетей для задачи идентификации цифробуквенной информации с багажных бирок в аэропорту // Современные технологии управления. ISSN 2226-9339. — №3 (93). Номер статьи: 9305. Дата публикации: 02.10.2020. Режим доступа: https://sovman.ru/article/9305/
Authors
Abstract
The article is devoted to the development and analysis of methods of identifying dynamic objects. A neural network with the architecture of SSD InceptionV2 has been developed to solve the problem of detecting luggage tags and barcodes. Several approaches are considered to solve the problem of identifying digital-letter information: Tesseract, SSD InceptionV2, OpenCV and a fully connected neural network. The operability of the methods on real images has been tested.
Keywords
computer vision, neural network, barcode, IATA airport code, TensorFlow, OpenCV, Python.
Project finance
The article was prepared with the support and within the framework of the DR-2020 event "International Competition of Scientific Works and Projects of Young Researchers" Digital Region - 2020 "" (Science and Education on-line)
Suggested citation
No items found. Application of deep neural networks for identification of alphanumeric information from baggage tags at airport // Modern Management Technology. ISSN 2226-9339. — №3 (93). Art. # 9305. Date issued: 02.10.2020. Available at: https://sovman.ru/article/9305/
Введение
Задача идентификации динамических объектов в видеопотоке является одной из наиболее востребованных в сфере технического зрения. На ее основе решается множество прикладных задач. В данной работе в качестве динамических объектов рассматриваются багажные бирки в сортировочной зоне аэропорта.
Актуальность данной работы обусловлена тем, что сотрудники сортировочных помещений аэропорта лишены возможности простой идентификации багажных бирок с помощью сканеров штрих-кодов потому, что база данных багажных бирок является недоступной для аэропортов.
Результаты исследований
Задачу идентификации багажной бирки можно разделить на две составляющие:
- Локализацию багажной бирки или ее основную часть – штрих-код.
- Распознавание цифробуквенной информации о коде аэропорта IATA.
В ранее описанных работах[1] для задачи локализации применялся разработанный нами алгоритм по поиску штрих-кодов на багажной бирке. Позже экспериментально было выявлено что данный алгоритм неработоспособен при различных условиях, таких, как: расстояние от багажной бирки до видео камеры, освещенность, ориентация; и имеет недостаток– в результате алгоритма сформируется область, информирующая о нахождении в этой области штрих-кода, но эта область в различных условиях не всегда соответствует области штрих-кода, что сводит на нет дальнейшую идентификацию информации о рейсе самолета.
Для решения задачи локализации багажной бирки с помощью нейронных сетей было рассмотрено несколько различных базовых архитектур нейросетей, доступных в TensorFlow Object Detection API, который является платформой с открытым исходным кодом, разработанной компанией Google на базе TensorFlow [2] и позволяющей легко строить, обучать и развертывать модели обнаружения объектов. Для целей данного исследования были рассмотрены следующие базовые модели: более быстрая R-CNN (Regions With CNNs) [3] с использованием Inception V2 [4], SSD (Single Shot Detector) [5] с использованием модели InceptionV2, и SSD, использующая MobileNetV2 [6]. Согласно исследованию [7] была выбрана архитектур SSD InceptionV2 так, как имеет более высокую скорость идентификации, потребляет меньше памяти, а точность идентификации сравнима с остальными.
Для обучения нейросети была создана обучающая выборка состоящая из 200 изображений с багажными бирками. Аннотация данных выполнялась программой LabelImg, с помощью которой выделяются границы интересуемого объекта и указывается класс к которому принадлежит данный объект.
В результате обучения на 240 эпохах точность нейросети локализации багажной бирки составила 95,3%. С помощью данной нейросети сужается область поиска информации о рейсе. Однако для более точного сужения области поиска, требуется искать область штрих-кода так, как зачатую информация о рейсе располагается над или под штрих кодом. Поэтому была создана нейросеть для решения задачи локализации штрих-кода. Для обучения использовалась та же база изображений, но при аннотации данных выделялись области штрих-кодов. По завершению обучения точность локализации области штрих-кода составила 96,7% при использовании данной нейросети. При эксплуатации данных нейросетей требуется намного больше вычислительных ресурсов чем на одну из них, поэтому для снижения вычислительной нагрузки было принято решение обучить одну нейросеть распознавать несколько классов объектов, нежели обучать несколько нейросетей распознавать по одному классу. По завершению обучения точность локализации объектов составила 89% при использовании данной нейросети. Результат работы нейросети представлены на рис. 1.

Рис. 1. Локализация багажных бирок и штрих-кодов нейросетью
Первым немаловажным шагом для корректного распознавания цифробуквенной информации является правильное отображение бирки, которое осуществляется алгоритмами и функциями библиотеки «OpenCV» [8] по следующему плану:
- Из изображения вырезаются участки идентифицированные нейросетью как штрих-коды.
- Сегментация области штрих-кода по алгоритму описанному в работе [1], рис. 2.б.
- Поиск наименьшей прямоугольной области, в которую можно заключить область штрих-кода используя функцию minAreaRec, рис. 2.в.
- Расчет угла поворота полученной прямоугольной области.
- Аффинное преобразование изображения используя функцию warpAffine, рис. 2.г.
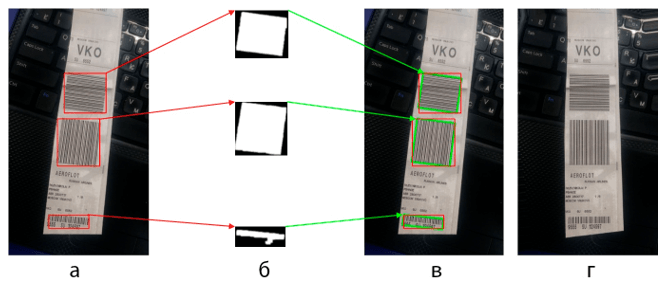
Рис. 2. Этапы достижения правильного отображения
Одним из первых вариантов решения задачи распознавания цифробуквенной информации была программа Tesseract. Это программный OCR-движок, который в настоящее время Tesseract поддерживается компанией Google, которая выкупила программу в 2006 году у HP и открыла исходные коды. Для работы с Tesseract в языке Python предусмотрена библиотека pytesseract [6]. Однако было выяснено, что программа показывает хорошие результаты только при идеальных условиях.
Поэтому было решено, для распознавания цифробуквенной информации использовать модель нейронной сети SSD InceptionV2, которая показала хорошие результаты по локализации багажных бирок и штрих-кодов. Обучение нейросети происходило на синтетической обучающей выборке, состоящей из изображений, на которых случайным образом были размещены символы различного шрифта. При этом каждый символ был повернут, масштабирован, искажен, зашумлен и обесцвечен для приемлемого разнообразия характеристик. Предлагаемым способом было создано 8000 изображений с цифрами и буквами для 36 различных классов. В результате обучения данной нейросети на 70 эпохах были получены результаты представлены на рис 3, из которого видно, что нейросеть хорошо детектирует коде аэропорта IATA, однако плохо справляется с символами маленького размера.

Рис. 3. Детектирование цифробуквенной информации
Для получения лучших результатов задачу разделили на 2 части: локализацию символов с помощью OpenCV и классификацию нейросетью.
Локализация символов выполнялась по следующим этапам:
- Захват области изображения, которая находится над штрих-кодом.
- Преобразование изображения в оттенки серого и инверсная бинаризация изображения.
- Нахождение контуров, используя функцию findContours, рис. 4.а.
- Чтобы исключить ложное распознавание, выполняется фильтрация по размерам контуров, т.е. ширина и высота контура должны пропорционально равны размерам буквы или цифры, рис. 4.б.
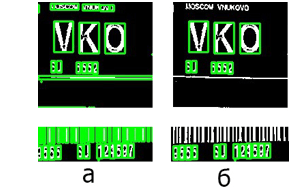
Рис. 4. а) Поиск всех контуров; б) Отсортированные контуры.
Для обучения классифицирующей нейронной сети была создана база из 76159 монохромных изображений цифр и букв разных шрифтов,
Архитектура нейронной сети обладает следующими параметрами:
- Входной слой — 784 нейрона, так как размер входных изображений 28х28 пикселей;
- 3 скрытых слоя по 512 нейронов;
- Выходной слой — 35 нейронов, где каждый нейрон отвечает за прогнозирование того или иного символа.
В результате обучения нейронной сети на 10 эпохах точность составила 95,88%.
Получение информации о символе заключенном в контур выполнялось следующим образом:
- Обрезаем изображение по контуру;
- Приводим изображение к размеру 28х28;
- Пропускаем через нейросеть;
- На выходе получаем массив из вероятностей;
- Поиск номера нейрона с наибольшей вероятностью и простановка символа над контуром соответствующего этому номеру, рис. 5.

Рис. 5 локализация и классификация цифробуквенной информации
Заключение
В ходе выполнения данной работы была разработана нейросеть с архитектурой SSD InceptionV2 для решения задачи детектирования багажных бирок и штрих-кодов. Рассмотрены несколько подходов для решения задачи идентификации цифробуквенной информации. Самый лучший результат был достигнут в подходе, где локализация выполнялась инструментами OpenCV, а классификация полносвязной нейросетью.

Читайте также




Библиографический список
- Обухов, П.С. Идентификация цифробуквенной информации с багажной бирки на основе нейронной сети/ П.С. Обухов, Е.А. Ивлиев, В.А. Ивлиев // Динамика технических систем (Ростов-на-Дону, 11-13 сентября 2019 г.). – Ростов-на-Дону, 2019, С. 65-68.
- Tensorflow documentation [Электронный ресурс]. Режим доступа — https://www.tensorflow.org/guide/keras?hl=ru
- Ren, S. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks/ S. Ren, K. He, R. Girshick, J. Sun // Advances in Neural Information Processing Systems. Vol. 39. 2015, P.1137–1149.
- Szegedy, C. Rethinking the inception architecture for computer vision/ C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, Z. Wojna// IEEE Conference on Computer Vision and Pattern Recognition. Vol.1. 2016, P.2818–2826.
- Liu, W. SSD: Single shot multibox detector/ D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.Y. Fu, A.C. Berg // European Conference on Computer Vision 2016. Vol. 1. 2016, P.21–37.
- Howard A.G. Mobilenets: Efficient convolutional neural networks for mobile vision applications./ A.G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, H. Adam // arXiv 2017, arXiv:1704.04861.
- Huang J. Speed/accuracy trade-offs for modern convolutional object detectors / J. Huang, V. Rathod, C. Sun, M. Zhu, A. Korattikara, A. Fathi, I. Fischer, Z. Wojna, Y. Song, S. Guadarrama // 30th IEEE Conference on Computer Vision and Pattern Recognition. arXiv 2017, arXiv:1611.10012v3.
- Tesseract wiki [Электронный ресурс]. Режим доступа — https://github.com/tesseract-ocr/tesseract/wiki
References
- Obukhov P.S., Ivliyev Ye.A., Ivliyev V.A. Identification of alphanumeric information from a baggage tag based on a neural network [Obukhov, P.S. Identifikatsiya tsifrobukvennoy informatsii s bagazhnoy birki na osnove neyronnoy seti/] // Dynamics of technical systems (Rostov-on-Don, September 11-13, 2019). – Rostov-on-Don, 2019, pp. 65-68.
- Tensorflow documentation [Электронный ресурс]. Режим доступа – https://www.tensorflow.org/guide/keras?hl=ru
- Ren, S. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks/ S. Ren, K. He, R. Girshick, J. Sun // Advances in Neural Information Processing Systems. Vol. 39. 2015, P.1137–1149.
- Szegedy, C. Rethinking the inception architecture for computer vision/ C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, Z. Wojna// IEEE Conference on Computer Vision and Pattern Recognition. Vol.1. 2016, P.2818–2826.
- Liu, W. SSD: Single shot multibox detector/ D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.Y. Fu, A.C. Berg // European Conference on Computer Vision 2016. Vol. 1. 2016, P.21–37.
- Howard A.G. Mobilenets: Efficient convolutional neural networks for mobile vision applications./ A.G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, H. Adam // arXiv 2017, arXiv:1704.04861.
- Huang J. Speed/accuracy trade-offs for modern convolutional object detectors / J. Huang, V. Rathod, C. Sun, M. Zhu, A. Korattikara, A. Fathi, I. Fischer, Z. Wojna, Y. Song, S. Guadarrama // 30th IEEE Conference on Computer Vision and Pattern Recognition. arXiv 2017, arXiv:1611.10012v3.
- Tesseract wiki [Электронный ресурс]. Режим доступа – https://github.com/tesseract-ocr/tesseract/wiki

